Zabbix is a powerful monitoring tool, that can easily become hard to control with the expansion of the infrastructure underneath.
One of the many features it offers is proxies, useful to monitor geo-dislocated devices. We happened to check a not-so-small Zabbix installation for a customer of ours, made of 1 server and about 12 proxies. Some of these proxies were very work-loaded, and needed some fine tuning.
But before analyze which kind of items were monitored and how they were organized, we first had to understand if hosts on which proxies were working were healthy. That’s where some useful Zabbix metrics come into play: Internal Checks.
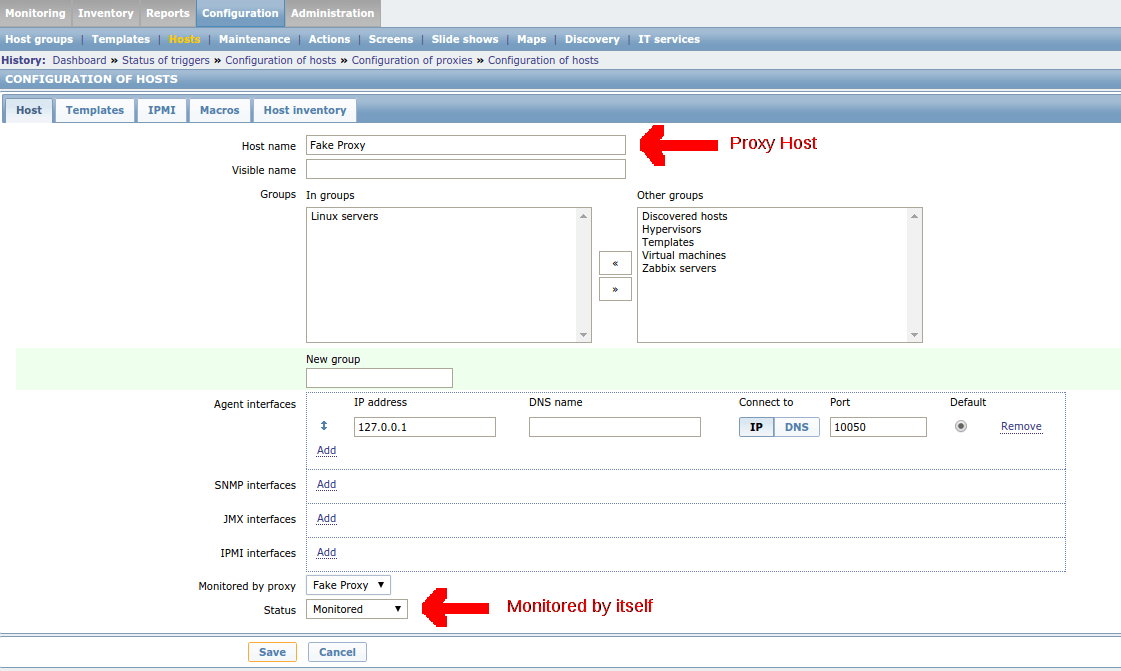
And that’s where we found a configuration error, with very small evidency if not checked in first place. All of the proxies were not monitored by themselves. What does this mean? That all of them shared same Zabbix server graphs, and was impossible to understand real behaviour of their internal, data gathering, value cache processes.
The solution? As showed in opening screenshot it’s enough to let them be monitored by themselves!
From then on, we were able to fastly identify slowness culprits and where to begin the tuning.